Normal Forms
The normal forms defined in relational database theory represent guidelines for database design. The normalization rules are designed to prevent update anomalies and data inconsistencies.
Normalization rules are divided into following normal form :
- First Normal Form (1 NF)
- Second Normal Form (2 NF)
- Third Normal Form (3 NF)
- Boyce-Codd Normal Form (BCNF)
- Multivalued Dependencies and Fourth Normal Form (4 NF)
- Join Dependencies and Fifth Normal Form (5 NF)
A relation is said to be in a particular normal form if it satisfies a certain specified set of constraints.
First Normal Form (1 NF) :
A relation is in first Normal Form if and only if all underlying domains contain atomic values only. In other words, a relation doesn’t have multivalued attributes.
For example : Consider a
STUDENT(Sid, Sname, Cname) relation
| Student : |
| SID |
Sname |
Cname |
| S1 |
A |
C,C++ |
| S2 |
B |
C++,DB |
| S3 |
A |
DB |
| SID : Primary Key |
|
⇐ |
Due to occurrence of MVA, the above relation is not in 1 NF. |
| ⇓ |
Solution :
Removal of MVA by inserting more rows |
| Student : |
| SID |
Sname |
Cname |
| S1 |
A |
C |
| S1 |
A |
C++ |
| S2 |
B |
C++ |
| S2 |
B |
DB |
| S3 |
A |
DB |
| SID : Primary Key |
|
⇐ |
The relation is in 1nF |
Another Example :
Consider another relation
Supplier(SID, Status, City, PID, Qty).
| Supplier : |
| SID |
Status |
City |
PID |
Qty |
| S1 |
30 |
Delhi |
P1 |
100 |
| S1 |
30 |
Delhi |
P2 |
125 |
| S1 |
30 |
Delhi |
P3 |
200 |
| S1 |
30 |
Delhi |
P4 |
130 |
| S2 |
10 |
Karnal |
P1 |
115 |
| S2 |
10 |
Karnal |
P2 |
250 |
| S3 |
40 |
Rohtak |
P1 |
245 |
| S4 |
30 |
Delhi |
P4 |
300 |
| S4 |
30 |
Delhi |
P5 |
315 |
| Key : (SID, PID) |
Let us assume each supplier has unique SID, and have exactly one Status code and Location(City) and further, Status is functionally dependent on City. A supplier can supply different parts(PID).
Key of Supplier relation is the combination of (SID, PID). The
Functional Dependency Diagram for Supplier relation is shown as :
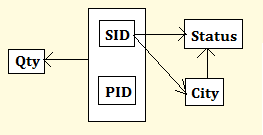
As there are no multivalued attributes(MVA), hence the Supplier relation is already in 1 NF.
But the Supplier relation has anomalies again which are :
Drawback of 1 NF :
- Anomalies :
- Deletion Anomaly – If we delete the tuple <S3,40,Rohtak,P1,245> , then we loose the information about S3 that S3 lives in Rohtak.
- Insertion Anomaly – We cannot insert a Supplier S5 located in Karnal, until S5 supplies atleast one part.
- Updation Anomaly – If Supplier S1 moves from Delhi to Kanpur, then it is difficult to update all the tuples containing (S1, Delhi) as SID and City respectively.
- Normal Forms are the methods of reducing redundancy. However, Sometimes 1 NF increases redundancy. It does not make any efforts in order to decrease redundancy.
Possibilities of Redundancy in 1 NF :
| a) When LHS is not a Superkey : |
| Let X → Y is a non trivial FD over R with X is not a superkey of R, then redundancy exist between X and Y attribute set.
Hence in order to identify the redundancy, we need not to look at the actual data, it can be identified by given functional dependency.
Example : X →Y and X is not a Candidate Key
⇒ X can duplicate
⇒ corresponding Y value would duplicate also. |
|
| b) When LHS is a Superkey : |
| If X → Y is a non trivial FD over R with X is a superkey of R, then redundancy does not exist between X and Y attribute set.
Example : X →Y and X is a Candidate Key
⇒ X cannot duplicate
⇒ corresponding Y value may or may not duplicate. |
|
]]>